미국에서는 자산을 1억 달러 이상 보유한 개인/기관 투자자는 매 분기마다 SEC에 자신의 매매 내역 보고서를 제출해야 한다. 이 보고서를 통틀어 Form 13F라 부른다. 이 13F 보고서에는 해당 개인/기관의 포트폴리오에 포함된 주식 종목 및 보유 규모가 언급되어있다.
따라서, 이 13F 보고서는 (비록 한 분기정도 늦지만) 워렌 버핏과 같은 투자 대가들이 어떻게 투자를 하고, 최근 동향은 어떠한지에 대해 정확히 알 수 있는 좋은 보고서이다. 많은 투자자들이 이 13F 보고서를 보고, 이에 기반해 투자 의사결정을 내리기도 한다.
금융 관련 서비스가 잘 구축된 미국답게, 이 13F 보고서도 보기 편하게 잘 정리해 둔 많은 사이트가 존재한다. 그 중 가장 정리가 잘 되어있다고 생각되는 사이트는 Dataroma 라는 사이트이다. 아래 링크를 눌러 들어갈 수 있다.
DATAROMA Invest Alongside Superinvestors
"I believe superior long-term performance is a function of a manager’s willingness to accept periods of short-term underperformance. This requires the fortitude and willingness to allow one’s business to shrink while deploying an unpopular strategy." -
www.dataroma.com
Dataroma에서 특정 종목을 선택하면, 아래 사진처럼 어떤 투자자가 어느 분기에 얼마만큼의 주식을 매수했는지 한번에 정리해 보여준다. 따라서 이를 보면서 최근 특정 종목에 큰손들이 많이 관심을 보이는지 여부를 쉽게 알 수 있다.

문제는, 우린 S&P500에 존재하는 500개 종목을 이렇게 하나하나 볼 시간이 없다는 것이다. 따라서, 위 사진처럼 Dataroma에서 이미 한 차례 정리해 준 13F 보고서 내용을 다시 파이썬으로 크롤링해 하나의 데이터 테이블로 만든 후, 이를 정량적으로 분석할 수 있도록 코드를 구현한다.
1. 파이썬 패키지 준비
이번 코드에서 쓸 패키지는 requests, beautifulsoup4 두 개가 있다. 이 두 패키지는 아래 코드처럼 pip을 통해 설치한다.
pip install requests beautifulsoup4다음으로 위 두 패키지 및 pandas를 사용할 수 있도록 import해 준다.
import requests
from bs4 import BeautifulSoup
import pandas as pd
2. 크롤링 준비
어떤 종목이든 크롤링할 수 있지만, 이번엔 연습이 목적이기에 애플 한 종목만 크롤링해 보도록 한다. Dataroma 웹페이지 크롤링을 위해, 첫 코드를 아래와 같이 작성해둔다.
크롤링 시 몇몇 웹페이지는 User-Agent값을 요구한다. Dataroma도 마찬가지로 User-Agent값을 요구하기에, 첫 번째 줄과 같이 header를 작성해 둔다.
다음으로 dataroma_data는 앞으로 크롤링할 애플의 분기별 13F 보고서 정보를 저장할 테이블이다.
마지막으로 L의 용도를 살펴보자. Dataroma에서 분기별 13F 보고서를 검색하면, 아래 사진과 같이 여러 페이지에 걸쳐 13F 보고서를 조회해야 하는 것을 확인할 수 있다. 때문에 2, 3, 4페이지 등 1페이지 이후의 페이지에 접속하려면 https://www.dataroma.com/m/activity.php?sym=AAPL&typ=a&L=3 이 링크처럼 마지막줄에 L=n으로 보고자하는 페이지 번호를 전달해줘야 한다. 각 페이지를 모두 크롤링하기 위해 L값을 변경해가며 모든 페이지의 13F 보고서 기록을 조회한다.

header = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36'}
dataroma_data = pd.DataFrame(columns=['13f_transaction'])
L = 0
3. 크롤링 및 데이터 입력
크롤링 및 데이터 입력 부분의 전체 코드는 아래와 같다. while문으로 묶여있어 따로따로 설명하면 헤깔릴 것 같아 일단 전체 코드를 첨부하고, 추가적으로 코드에 대한 설명은 아래쪽에서 다시 설명한다.
while True:
soup = None
try:
L += 1
url = 'https://www.dataroma.com/m/activity.php?sym={}&typ=a&L={}'.format('AAPL',L)
html = requests.get(url,headers = header)
soup = BeautifulSoup(html.text, 'html.parser')
except:
break
trs = soup.select('tbody')[0].select('tr')
if len(trs) == 0:
break
for tr in trs:
if 'q_chg' in str(tr):
month = str(int((int(tr.select('b')[0].text[-1])*3 + 2)%12))
Q = tr.select('b')[1].text + '-' + month + '-1'
else:
transact = tr.select('.sell')
sign = -1
if len(transact) == 0:
transact = tr.select('.buy')
sign = 1
amt = int(transact[1].text.replace(',' , '')) * sign
dataroma_data = dataroma_data.append({'date':Q,'13f_transaction':amt},ignore_index=True)
dataroma_data = dataroma_data.groupby('date').sum()[::-1].reset_index()
dataroma_data = dataroma_data.set_index('date')
먼저, while 문을 쓴 이유는, 과거 13F 보고서 기록이 총 몇 페이지까지 있는지 알 수 없기 때문에, 아래 코드처럼 에러가 나기 전까진 계속 L값을 높여가며 존재하는 모든 과거 기록을 크롤링하기 위함이다.
아래 코드에서 url은 Dataroma에서 AAPL 종목의 13F 리스트가 나열된 각 페이지를 크롤링하기 위한 주소이며, requests와 BeautifulSoup를 통해 텍스트화된 html 소스코드를 받아온다.
만약 url을 크롤링하는 과정에서 에러가 나거나, 크롤링한 데이터(soup변수의 tbody에서 tr이 포함된 값을 전부 선택)가 빈 칸인 경우, 이미 해당 종목의 모든 13F 데이터를 받아온 것으로 판단해 while문을 빠져나간다.
# 위 전체 코드의 설명입니다
soup = None
try:
L += 1
url = 'https://www.dataroma.com/m/activity.php?sym={}&typ=a&L={}'.format('AAPL',L)
html = requests.get(url,headers = header)
soup = BeautifulSoup(html.text, 'html.parser')
except:
break
trs = soup.select('tbody')[0].select('tr')
if len(trs) == 0:
break
# 위 전체 코드의 설명입니다
만약 위 코드를 실행시켜 위와 같이 soup 변수에 정상적으로 html값이 저장이 됐고, 리스트 변수 trs에 tr(테이블 각 row)들을 뽑아 저장해 뒀다면, 이제 각 tr 내 내용을 살펴보며 버릴 값과 보유할 값을 구분한다. 우리에게 필요한 건 해당 거래의 시점(ex: 2020년 1분기), 거래의 방향(매수 혹은 매도), 그리고 거래 규모(ex: 150,000주) 세 가지이다.
먼저 해당 거래의 시점을 알아내기 위해 tr 내에 'q_chg' 라는 단어가 포함되어 있는지 확인한다. Dataroma에선 해당 데이터의 분기를 표시할 때 <tr class="q_chg"><td colspan="6"><b>Q3</b> <b>2017</b></td></tr> 이처럼 class를 q_chg로 설정하기 때문에, 해당 row에 q_chg가 포함되었는지 여부를 체크해 현재 row가 몇 분기인지를 알 수 있다. 각 보고서별로 제출 일자가 조금씩 다르기 때문에 1분기는 5월 1일, 2분기는 8월 1일, 3분기는 11월 1일, 4분기는 2월 1일로 통일시킨다.
다음으로 tr내에 sell 혹은 buy가 포함되었는지 여부를 체크한다. 이를 통해 <td class="sell">171,941</td>이나 <td class="buy">149,941</td> 와 같이 매수/매도 여부와 거래 규모를 동시에 체크할 수 있다.
# 위 전체 코드의 설명입니다
for tr in trs:
if 'q_chg' in str(tr):
month = str(int((int(tr.select('b')[0].text[-1])*3 + 2)%12))
Q = tr.select('b')[1].text + '-' + month + '-1'
else:
transact = tr.select('.sell')
sign = -1
if len(transact) == 0:
transact = tr.select('.buy')
sign = 1
amt = int(transact[1].text.replace(',' , '')) * sign
dataroma_data = dataroma_data.append({'date':Q,'13f_transaction':amt},ignore_index=True)
# 위 전체 코드의 설명입니다이렇게 만들어진 dataroma_data값은 아래 표와 같다.
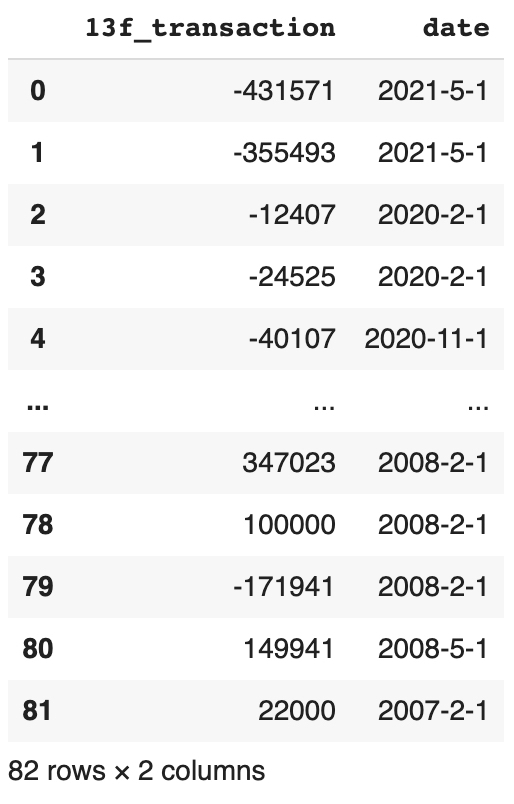
각 개인/기관이 개별적으로 13F를 제출함에 따라 한 분기에 한 개 이상의 13F 보고서가 발행되기에, 위처럼 date 컬럼에 중복되는 분기가 발생한다. 이를 더 보기 쉽게 만들기 위해 동일한 분기에 일어난 거래 액수를 하나로 합치도록 한다.
# 위 전체 코드의 설명입니다
dataroma_data = dataroma_data.groupby('date').sum()[::-1].reset_index()
dataroma_data = dataroma_data.set_index('date')
# 위 전체 코드의 설명입니다이렇게 할 경우, dataroma_data는 아래와 같이 바뀐다. 각 분기별로 총 거래 규모를 계산해 나열했기 때문에, 한 눈에 쉽게 개인/기관의 거래 방향성을 알 수 있다. 이를 향후 투자에 활용해 유용한 결과를 만들 수 있을 것으로 기대한다.
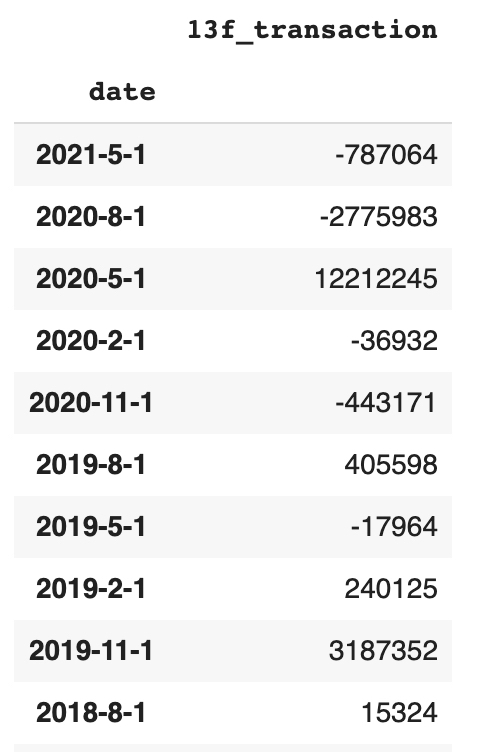
예시로 위 데이터를 간단히 해석해보면, 13F 보고서 상 AAPL 종목은 대규모 개인/기관에 의해 '21년 1분기에 787,064주 매도되었고, '20년 3분기에 -2,775,983주 매도 .... 등으로 해석 가능하다.
위 코드에서 애플의 티커를 나타내는 'AAPL'을 다른 종목의 티커로 바꾸면, 즉시 해당 종목의 13F 보고서 데이터를 불러올 수 있다.
'퀀트 분석 > 퀀트 기초' 카테고리의 다른 글
| [Python] 파이썬으로 주식 보조지표 구하기(RSI, MACD 등) (9) | 2021.08.14 |
|---|---|
| [Python] 주식 종목 간 상관관계 분석 (1) | 2021.08.10 |
| [Python] FMP API 사용해 미국 재무제표 데이터 불러오기 (7) | 2021.04.04 |
| [Python] Yahoo Finance API로 주가 데이터 받아오기 (8) | 2020.08.20 |
| [Python] FRED에서 API로 경제 데이터 불러오기 (3) | 2020.07.22 |




댓글